Parsing JSON and ATOM Twitter Search Results in Go
Originally uploaded by ajstarks
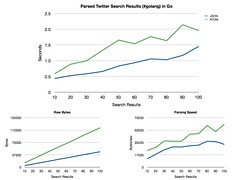
The top chart shows the time a Go program takes to search twitter, parse the results, and output the tweets, varying the number of search results from 10-100. The blue shows the results for JSON, the green for ATOM (XML).
Also depicted is the number of bytes to parsed, and the resulting parsing rate.
The conclusion is that JSON is more efficient; HTTP rates are constant, but JSON requires less data, with less complex data structures to unmarshal. Both methods deliver identical results:
ts -f json -n 10 '#golang'
RT @koizuka: RT @tokuhirom: #golang は C/C++ のかわりにつかうというよりは。python のかわりに使うという領域の方がおおきいんだとおもう
RT @tokuhirom: #golang は C/C++ のかわりにつかうというよりは。python のかわりに使うという領域の方がおおきいんだとおもう
Here is the program: it demonstrates command line parsing, error checking, http processing and unmarshaling both JSON and XML.
// ts -- twitter search
//
// Anthony Starks (ajstarks@gmail.com)
//
package main
import (
"fmt"
"http"
"io"
"io/ioutil"
"flag"
"os"
"xml"
"json"
)
type JTweets struct {
Results []Result
}
type Result struct {
From_user string
Text string
}
type Feed struct {
XMLName xml.Name "http://www.w3.org/2005/Atom feed"
Entry []Entry
}
type Entry struct {
Title string
Author Person
}
type Person struct {
Name string
}
type Text struct {
Type string "attr"
Body string "chardata"
}
var (
format = flag.String("f", "atom", "Output format (json or atom)")
nresults = flag.Int("n", 20, "Maximum results (up to 100)")
since = flag.String("d", "", "Search since this date (YYYY-MM-DD)")
)
const (
queryURI = "http://search.twitter.com/search.%s?q=%s&rpp=%d"
outputfmt = "%s \u27BE %s\n"
)
func ts(s string, how string, date string, n int) {
var q string
if len(date) > 0 {
q = fmt.Sprintf(queryURI+"&since=%s", how, http.URLEscape(s), n, date)
} else {
q = fmt.Sprintf(queryURI, how, http.URLEscape(s), n)
}
r, _, err := http.Get(q)
defer r.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
return
}
if r.StatusCode == http.StatusOK {
switch how {
case "atom":
readatom(r.Body)
case "json":
readjson(r.Body)
}
} else {
fmt.Fprintf(os.Stderr,
"Twitter is unable to search for %s as %s (%s)\n", s, how, r.Status)
}
}
func readatom(r io.Reader) {
var twitter Feed
err := xml.Unmarshal(r, &twitter)
if err != nil {
fmt.Fprintf(os.Stderr, "Unable to parse the Atom feed (%v)\n", err)
return
}
for _, t := range twitter.Entry {
fmt.Printf(outputfmt, t.Author.Name, t.Title)
}
}
func readjson(r io.Reader) {
var twitter JTweets
b, err := ioutil.ReadAll(r)
if err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
return
}
jerr := json.Unmarshal(b, &twitter)
if jerr != nil {
fmt.Fprintf(os.Stderr, "Unable to parse the JSON feed (%v)\n", jerr)
return
}
for _, t := range twitter.Results {
fmt.Printf(outputfmt, t.From_user, t.Text)
}
}
func main() {
flag.Parse()
for i := 0; i < flag.NArg(); i++ {
ts(flag.Arg(i), *format, *since, *nresults)
}
}
1 comment:
Good fill someone in on and this post helped me alot in my college assignement. Thanks you on your information.
Post a Comment